


This is the final paper presented by Giuseppe Forte, a recent graduate of the Global Digital Marketing and Localization Certification (GDMLC) program. This paper presents the work being produced by students of The Localization Institute’s Global Digital Marketing and Localization Certificate program. The contents of this Paper are presented to create discussion in the global marketing industry on this topic; the contents of this paper are not to be considered an adopted standard of any kind. This does not represent the official position of Brand2Global Conference, The Localization Institute, or the author’s organization.
Introduction
The European Union meant as ‘an economic and political union between 28 European countries[1]’ works with several Institutions and Agencies which are specialised in a wide variety of specialised domains. All Agencies and Institutions own a website where it is possible to read about their missions and their work. Some of them are mainly informative websites, so people can get information about specific topics, like health and safety at work (EU-OSHA) or chemical legislation for the benefit of human health and the environment (ECHA) and so on. Some others provide also services to the citizens, such as for instance registration of trademarks (EUIPO).
Although the European Commission has implemented a Multilingualism Policy[2] ‘to promote Europe’s rich linguistic diversity and to promote linguistic learning’, European Union Agencies and Institutions Websites have not adopted it in a harmonized way. Some of them have done it extensively, and some others have not started yet, or have worked on it in a special way (see example of the European Medicines Agency of the European Union in the paragraphs below).
For those websites where multilingualism has been adopted – meaning that the content is fully or partially available in the 24 EU languages and in some cases in other non-EU languages (Icelandic or Norwegian, for instance) – if we give a look at them, in their different linguistic versions, can we really talk about Localization? According to the idea of the EU Fundamental Rights Charter ‘to respect linguistic diversity’, can we assume that this respect of linguistic diversity takes the form of a proper Localization?
With these questions in mind I tried to briefly analyse some of the EU websites (only agencies and not institutions) and I tried to setup the basis of a possible extensive work to be carried out in this direction. This paper provides, therefore, just a series of facts and ideas on the topic of Localisation to reach various digital markets: the ones of the EU and, why not, beyond EU borders.
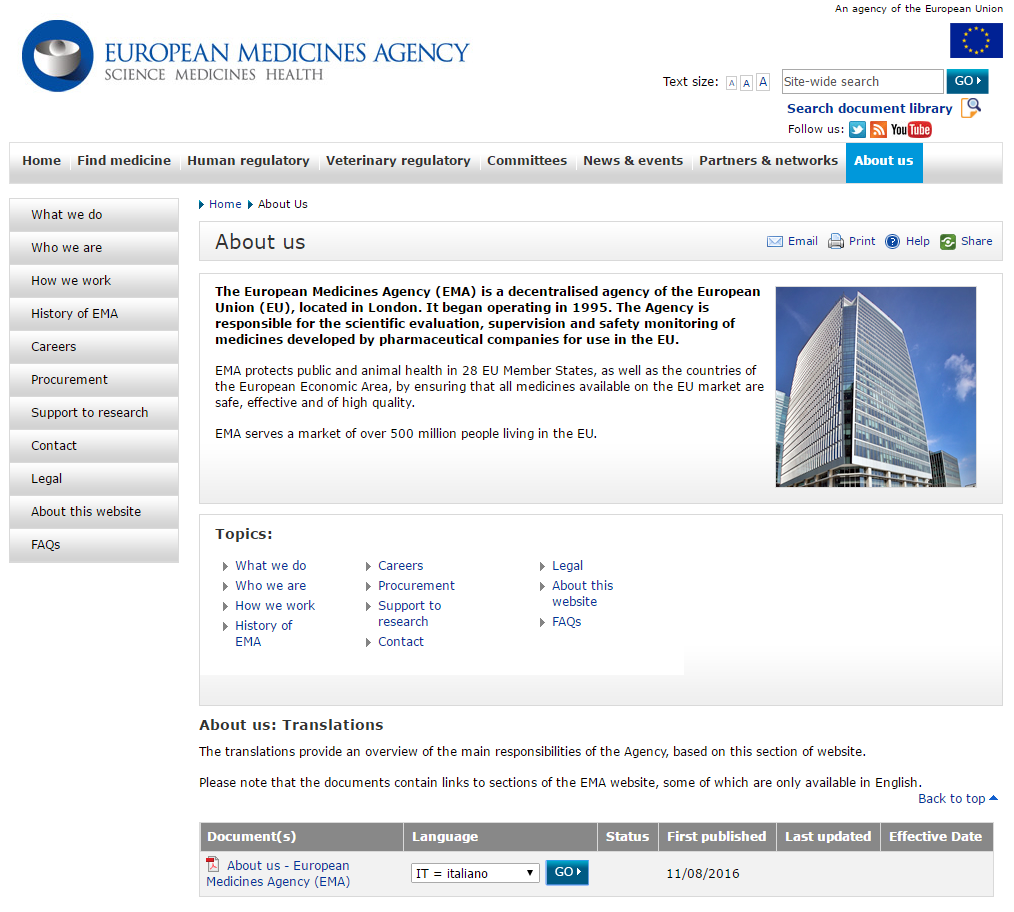
Figure 1 – Example of how EMA provides information about its website in other EU languages
Contextualisation and methodology
To realize this job I have conducted a series of researches on the European Union institutions and agencies websites, and I have re-used information that I had the chance to gather in one of my previous master’s thesis on a similar matter: ‘Optimizing web pages content localisation project management created and managed in a CMS[3]’, Giuseppe Forte, Seville, 2015.
In this paper I am going to present a series of reflections on whether it is possible or not to talk about Localisation when analysing European Union Agencies websites, and if yes, to which extent.
In order to make it possible, I think that showing some examples on how some agencies work would give us a better idea to answer our questions. On the basis of my previous job realised in 2015, I will show some of the main technical challenges that both a Language Service Provider (LSP) and a Client (in this context a possible EU agency) have to face when producing content that needs to be made available in all EU languages. To do that I have had the chance to analyse the job carried out by two EU agencies: one that in our context plays the role of the client and the other one that plays the role of an LSP.
Finally, it would be interesting to realise a detailed study in collaboration with the EU to try to understand their strategy and check what they think about this topic.
Why ‘Principal Issues in European Union Website Localisation’
The reason why I decided to analyse a little area of the possible many challenges or issues in website localisation comes from my personal professional experience. When I started working in the translation world, I could see from my very initial steps that technology was covering a very important role. In addition to that, I must admit that I have always liked technologies and therefore I knew from the beginning that Localisation, in general, could be an excellent ground for my career.
As a Translation Technologist, or Localisation Engineer, working in between translation and localisation, I have seen a lot of confusion on the use of the terms Translation and Localisation. This is not something new I guess. But what called my attention in several occasions is the way in which many people abuse of one of these two terms when trying to provide a service.
European Union has to deal with 24 languages, each one of them representing one or more than one culture (think of French in the EU: it is officially spoken not only in France, but also in Belgium and Luxembourg). EU agencies websites provide valuable information in many specialised areas that are not only consulted by EU users, but worldwide. We can imagine therefore the challenges of the EU Commission to monitor all EU agencies websites and to establish probably a common approach.
By giving a look at how some EU agencies handle translations of web content, we will have an idea of the many challenges that the EU has to face. The requests that I will quickly show below as examples, seem to be a growing business type in the localisation world and to acquire more and more importance. If some time ago website localisation was purely something that, apart from the academic environment, only LSPs would consider and promote to possible clients, nowadays it is possible to see not only experts in this field (or related fields) talking about it and promoting it, but also marketers or people involved in the business growth[4] of any company willing to expand their business (the Global Digital Marketing and Localisation Certification provided by the Localisation Institute gives an extended insight on this subject).
EU Website Localisation requests characteristics
The website localisation requests analysed in this paper present the following characteristics:
- It is not clear whether we should talk about website translation or website localisation requests;
- The type of website in question is informative (as many other website of the EU), as opposed to other types of websites – commercial, blogs, etc. – and therefore with its own characteristics;
- This kind of requests can be found in some European Union websites in which content is usually available in all the languages of the EU;
- They do not contain any multimedia products (no videos, flash, etc.), meaning that they only contain textual content coming from Content Management Systems which have translation management modules that streamline content validation, translation processes and functional, cosmetic and linguistic testing procedures;
- The content is usually created and published in English and is to be translated into several European Union languages, in some cases in less than 24 hours and it’s usually ‘news content’, which means that in terms of volumes, it’s not that much, it’s rather a few short paragraphs;
- This kind of requests is very common to be found in the market nowadays as companies are trying to reach more peoples by crossing national borders;
- And finally, there is a technological element in their processing that makes them very interesting.
The reasons why EU creates this kind of requests are several, but the most important one is probably the right of EU citizens to access specialised information in their own language(s).
In the following sections of this document we will see where all these considerations are placed in website localisation and I will try to solve some doubts about the use of ‘website localisation’ terminology.
Translation or Localisation?
I already anticipated the difficulty in deciding whether for the type of requests analysed in this job we can talk about localisation or it’s rather more correct to talk about website translation. This question arises from the fact that nowadays there seems to be a bit of confusion on the use of these two terms, especially with people who are no really familiar with Localisation as a discipline (and even with translation).
Schäler, R. (2011) defines Localisation as ‘Linguistic and cultural adaptation of digital content to the requirements and locale of a foreign market, and the provision of services and technologies for the management of multilingualism across the digital global information flow’. In this definition it is possible to note the typical ‘linguistic and cultural adaptation’ elements of Localisation. But if we compare this definition to others[5] we note that Schäler adds a technological element that in this context represents a key element.
Due to the textual nature of this kind of requests, people tend to say that these requests can be treated as regular translation requests as they do not contain any cultural elements, that’s why we can talk about website translation. In such cases, we can see LSPs, for instance, who refer to mirror sites: ‘A mirror of your current site in the language or languages of your choice. The result is a bilingual or multilingual replica of your website’.[6]
Cultural elements are not that visible in this type of requests, or might be completely absent. European Union websites, for instance, seem to be as much neutral (or standardised) as possible, in order not to have to localise their content according to a specific locale. In the ‘Web Translation as a Genre’ publication by the European Commission (2009), under the Localising to meet reader attitude chapter, we can read: ‘EU legal texts are drafted in such a way as to be compatible with any national legal system, avoiding as far as possible the need to localise language versions’. This shows that in general there might be little need to adopt ‘proper localisation’ in terms of culture, national law, economy or climate elements, for instance.
On the other hand, if we consider the other face of localisation, the technical part, we can see quite a lot of elements that make it worth mentioning. Esselink (2000) emphasises the technical characteristics in handling website localisation requests: ‘As a result, web site localisation is more comparable to software localisation than online help localisation, i.e. extensive linguistic and functional testing will be required’. Without going into further details, the number of challenges with respect to technicalities in handling this specific type of website localisation requests is such as to consider it as a critical element since if they were not handled in a specific way – completely different from a traditional translation request – we would run into several issues that could seriously compromise the translation work and its primary function.
Cultural versus technical elements:
The following example shows a page of a news article taken from the EU-OSHA website. In red, it is possible to see some of the ‘localisation elements’ identified.
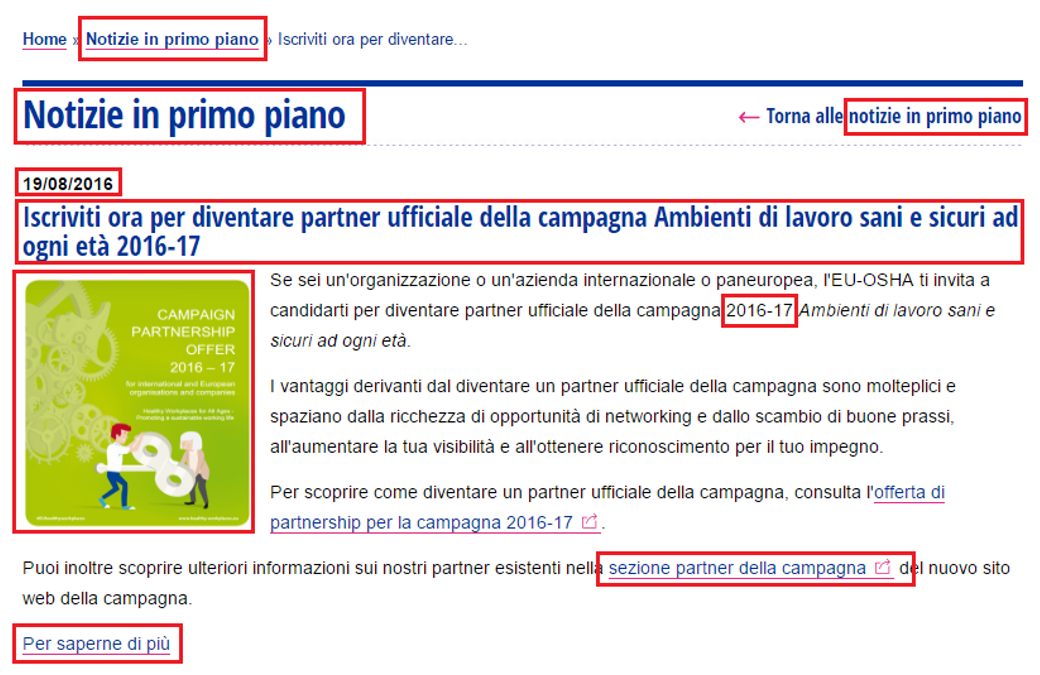
Figure 2 – Example of an EU website (EU-OSHA) and some ‘localization elements’
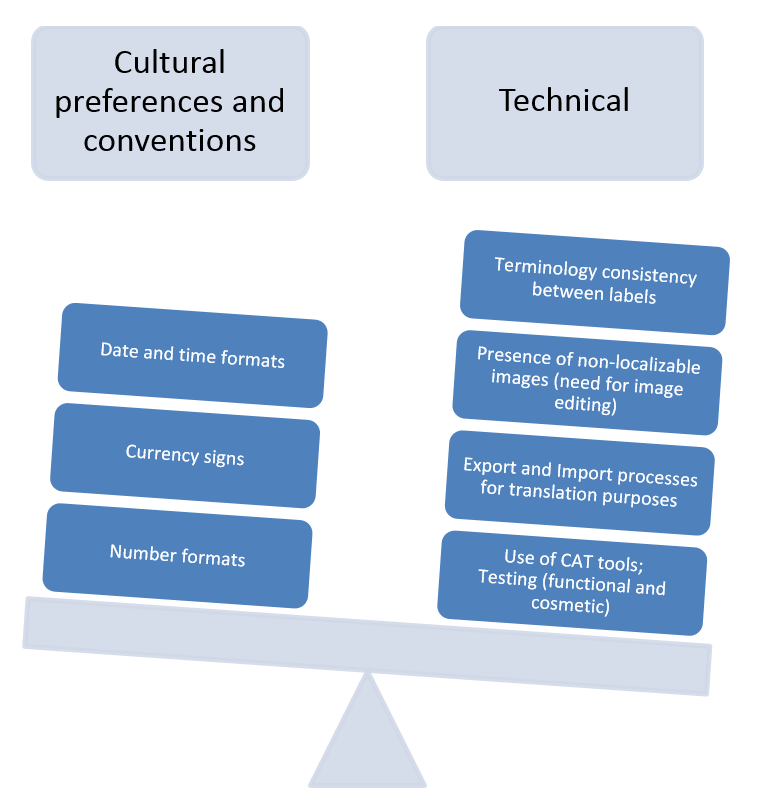
If we try to analyse in a simplistic but still realistic way the different weights of technical and cultural elements in this type of requests, we would probably see on one side typical elements usually considered ‘cultural specific’ of a given locale, such as date and time formats, currency signs or numbering formats, and on the other hand we would see that the number of technical processes needed to treat these files, which would be quite heavier.
The European Commission, by referring to EU websites (in particular to the ones managed by the Commission itself) states the following: ‘Strictly speaking, the concept of localising is not particularly well adapted to web contents. The web is by definition a non-local environment, and the author, translator or publisher of a web page cannot control the geographical distribution of its readers’.
So we can conclude that the cultural element of localisation in this kind of requests seems to be quite weak because of the neutrality or standardisation of their textual content and layout (in the EU there is no need to change a site to the right-to-left reading mode, for instance). But is this enough to define this kind of requests as non-localisation requests?
Well, if we analyse the considerations made so far I would answer no. On the contrary, I would rather say that this kind of requests need to be considered as localisation requests as the technical treatment need to process them is such as to consider them different from any other type of traditional translation requests, and that proper workflows and processes need to be setup in order to return high quality (or even acceptable) results.
In the following sections we will see some of the processes required to process them that proves this view.
Technical processing
Before we start showing why processing this kind of requests needs a specific attention, it would be better to provide a bit more of context.
This kind of requests present a series of characteristics that we have already seen in the previous paragraphs of this job. What still is important to analyse is how a possible LSP could manage them. If we think that this kind of requests are systematic, meaning that the website owner publishes content on a daily basis and needs it to be translated into all EU languages (or non-EU ones in some cases), it is obvious that a specific agreement and workflow need to be established. Moreover, if an LSP is rather providing translation services (translation of traditional documentation) we can understand that for this kind of requests the traditional translation process would not work at all as we explained in the previous chapters and for the reasons that will be mentioned in the next few paragraphs.
Content information: CMS and Export formats
This type of requests contains text only and this content is usually generated in a CMS and exported for translation.
- Analysis (LSP side)
This content is exported from the CMS in XML. Nowadays CMS are quite advanced and allow to export their contents in several ways. If we think of an LSP working for a given number of EU agencies or institutions (or simply clients), we can imagine the challenges in dealing with several CMS and with the types of export of each agency/client. From a technical point of view this could ‘easily’ be solved, meaning that there should be an analysis phase for each new export format in which a Localisation Engineer would analyse that given format and get familiar with it in order to process it with the proper tools. Once this analysis is concluded, then the tools would be setup and the processes adjusted. The same processes would be repeated for each new export format and client.
It is obvious that this is a time consuming process that requires special attention and that an LSP cannot ignore. On the other hand, this is something that, if properly established, can easily be handled and without any major efforts, at least as far as competencies and technologies resources are available.
Another idea to reduce the risk of creating too many adapted processes, one for each client, would be to propose a harmonisation on the export modules of any CMS involved. In the case of the EU agencies, this idea would not sound that difficult, being them all part of the same ‘family’. In this way each CMS would return the same export format. Let’s think of the case of an XML, all CMS should be adapted in a way that the translatable content is exported in an XML file that would follow a predefined XML Schema. By sharing the XML Schema across the EU agency, this would make all this possible.
The advantages of using a shared Schema would be many, as for an LSP (or the internal translation services of the EU), there would not be any need to create several customisations. One would work for all of them, regardless of the CMS used by each agency.
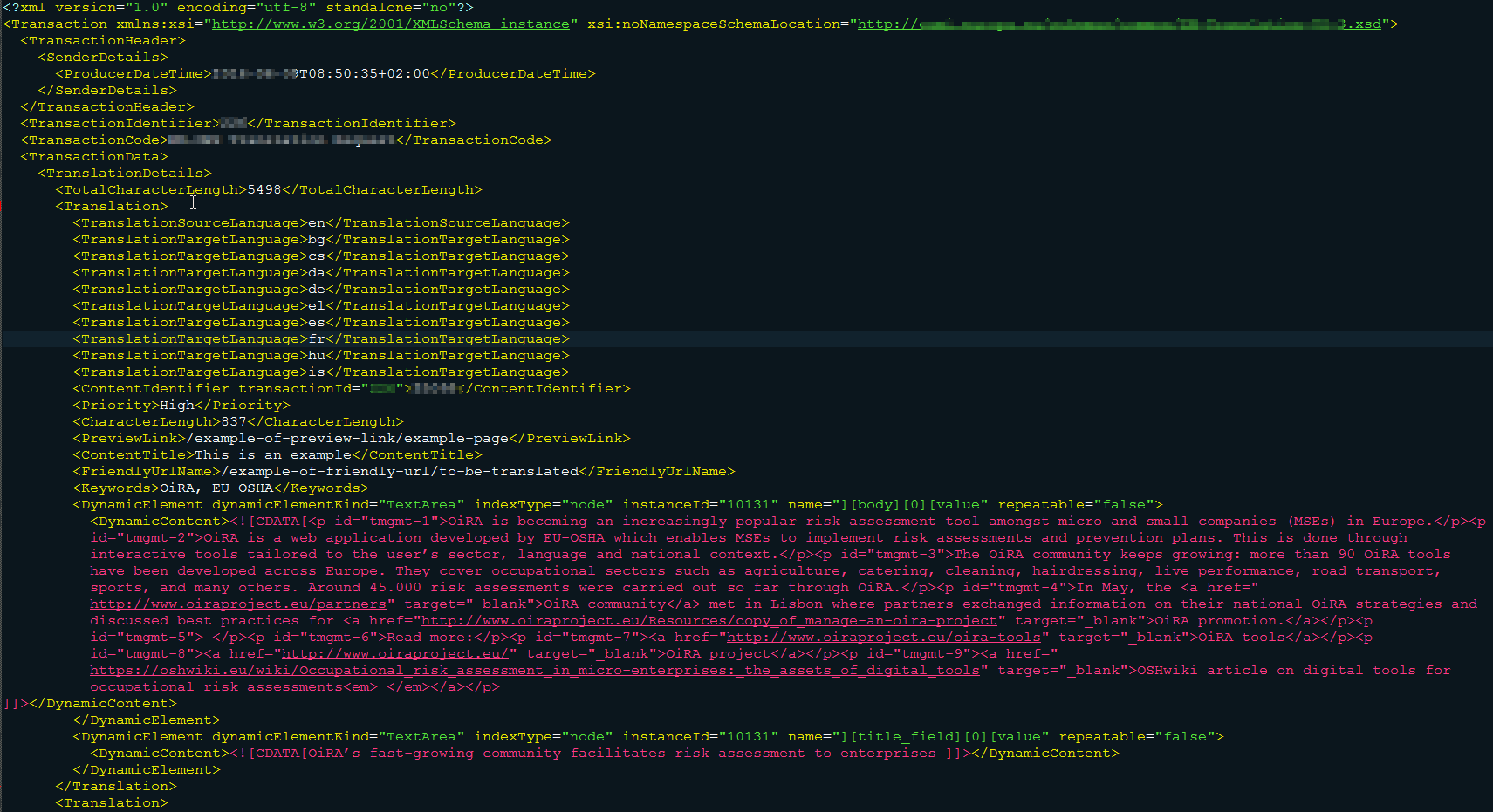
Figure 3 – Example of XML file[7]
Submission for translation
The way content is organised in a CMS and the way it is exported for translation might vary from one CMS to another. In the case analysed in this job we have given for granted that the option to send for translation the content of a CMS is through its export into an XML format. We know that nowadays there are several possibilities to carry out website localisation, like for instance Website Translation Proxy, but the export option is still very common and usually provides flexibility in terms of number of clients that could request this service. On the other hand it is still important to highlight that whenever there is an export of content from one platform to another, the risk to make mistakes or to be in front of technical issues (due to conversion processes, for instance) is quite high.
2. Mark for translation (client side)
When a new content, or a news content is created in such website type, it is necessary to mark that content for translation in order to export it into XML. This can be done through modern CMS that thanks to workflow options and ‘markup options’, allow webmasters to select a given part of a webpage and to send it to a ‘translation manager’ module where several requests can be grouped and sent for translation as a unique file.
This process allows webmasters to work in a very flexible way as they can mark for translation only the recent new or edited content of an existing webpage, with no need to re-export the whole page. But if on the one hand this helps the webmaster, on the other hand this creates a series of issues when it gets to translation as this content might be completely without context.
3.Request Submission (both client and LSP side)
As the content marked for translation can be grouped into a translation manager – a special module that allows to merge all content marked for translation into one single XML and that also allows to carry out some automated tasks, such as word counting (based on a predefined parser) – and can be exported into a specific XML file, the only thing left on the client’s side is to send it to an LSP.
E-mail exchanges for this kind of job is not really the best solution, that’s why LSPs usually ask clients to submit their request through the LSP’s Workflow Management System. In cases in which several clients might send several requests to the same LSP in a systematic way, it could be useful to use web services that would allow the client’s CMS to communicate with the LSP Workflow Management System. This latter would read the metadata information of the XML files (or simply sent by the CMS) and create automatically a request that could be pre-processed automatically.
Pre-processing
The pre-processing phase is very likely to be the one that presents the most evident technical elements of a website localisation requests.
As it was mentioned in the previous paragraphs, the analysis of the format sent by the client is essential to setup a proper environment. This analysis actually allows Localisation Engineers to carry out the proper steps to adapt tools, or simply select the proper tools, to automate repetitive and complex tasks as much as possible.
4. Translation Memory Systems and CAT Environments
In this regard I think it is important to mention that the use of translation memory systems is quite essential for this kind of requests. There are several reasons why this is so important (just think of the terminology consistency between several pages of the same webpage) and one of them is definitely the automation of some tasks and the limitation of human errors.
By setting up tools properly, in fact, it is possible to automate tasks such as the parsing of complex XML files. Although translators nowadays are familiar with complex formats, there is always the risk to find someone who is not familiar at all with such formats, or the risk to corrupt non‑translatable content (XML markup code), resulting therefore in inefficiency or wrong outputs. The use of CAT tools can therefore limit many of these issues and contribute to produce high quality results.
The following image shows an example of complex XML: it contains embedded HTML and the tool should be able to extract the translatable content of some elements of the XML itself and most elements of the embedded HTML:
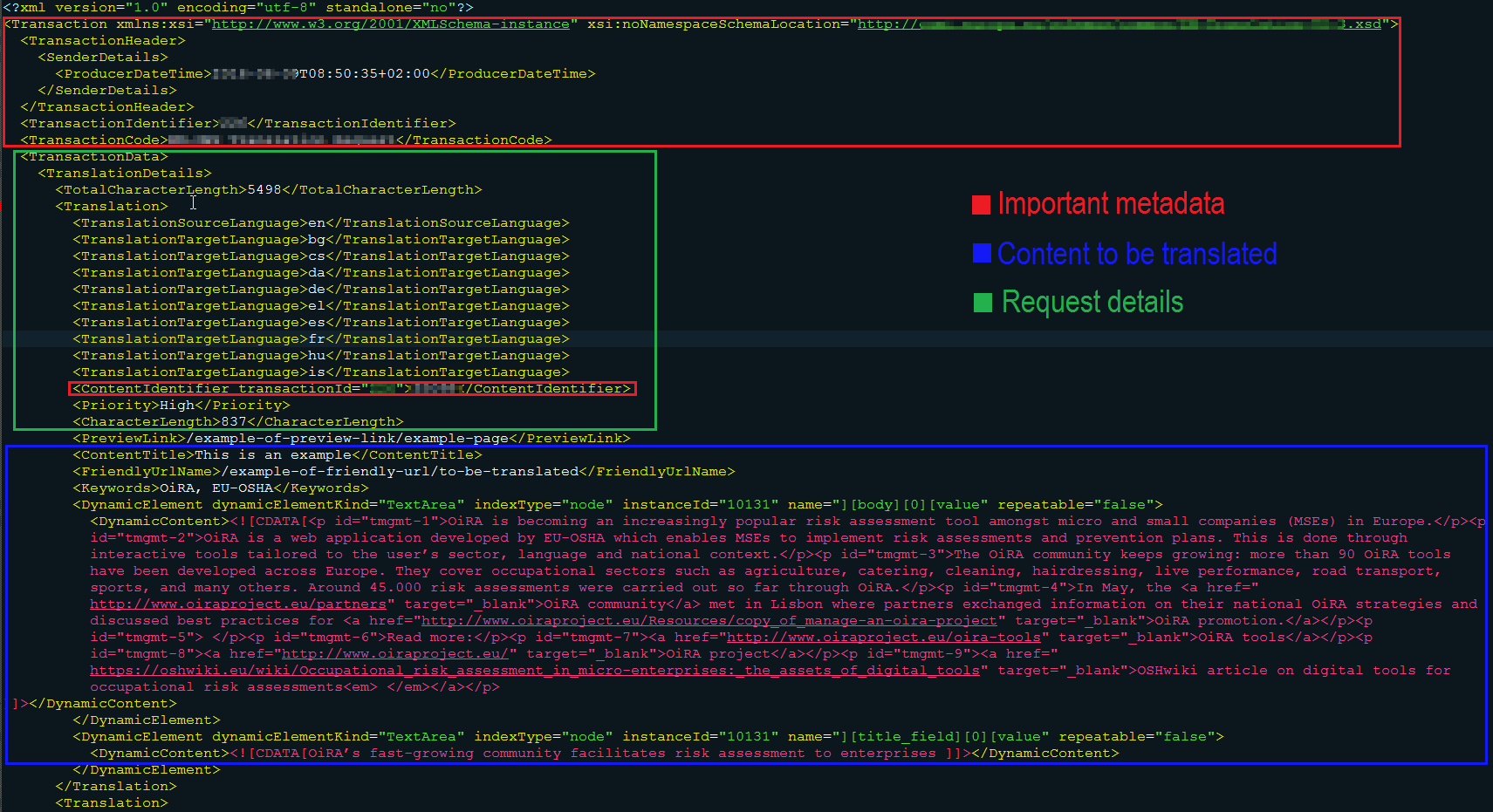
Figure 4- Example of XML and display of its structured content
To do that it is necessary to use a CAT tool able to process XML files with embedded HTML. The parser should be customised in a way to filter only the translatable content (not all metadata might need to be extracted for translation, for instance) and to leave aside the non-translatable one. This task is very important and must be done precisely, otherwise we can risk to have translatable content not exported for translation (or the opposite) and therefore influence the word count negatively.
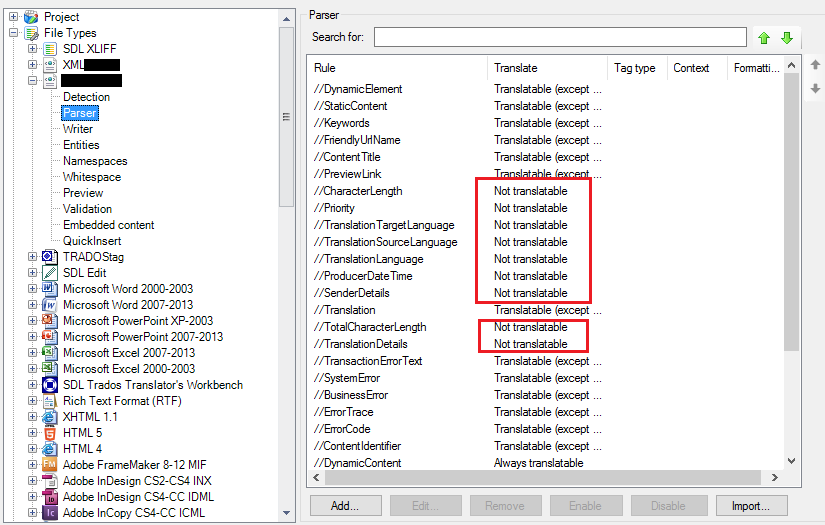
Figure 5 – Example of Parser customisation in a CAT tool
CAT tools like SDL Trados Studio, support this functionalities in a more or less easy way. In the above image, we can see that the parser of the XML filter has been adapted according to the need of this kind of XML request. By having a look at the parser, we can see some elements like Total Character Length that are marked as Not translatable. This is important to create a ‘CAT environment’ for a translator who has the possibility to work on a user‑friendly editor in which there is nothing but translatable content and that at the same time is the same environment used for traditional translation requests.
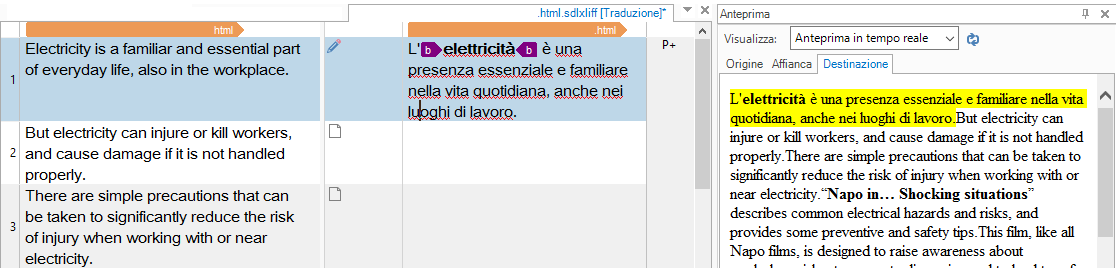
Figure 6 – Example of Editor and preview option in a CAT tool
By working in the same environment, there is no need to change tools, and translator’s user experience with the tool will definitely improve over the time.
The advantages of using a CAT environment are many: not only to streamline and speed up processes, or to be consistent from a terminology point of view and reuse content already translated, but also to make use of several important features like grammar and spell checkers, quality assurance profiles, use of dictionaries and many more. All this would result in many gains in productivity, quality, and cost and time savings.
Translation phase: context and preview
The translation phase is probably the most challenging one in this process. If we analyse what it was said so far, it is obvious that we are talking about a process in which content is created on a website (in a CMS), that is exported into an XML file for translation and that then is parsed by some filters in a CAT tool that would result into a translation request to be carried out in the editor of such CAT tool, the same as the one used for traditional translation requests.
The first observation to be made is the fact that this web content might come from several webpages and without any context. No CAT tool is able to provide context if the input does not contain it. The XML files show, therefore, a weak point, which is the fact that the exported content comes without any context, and therefore translators are in front of sentences not related to each other, one after the other: it basically does not allow the translator to understand if a sentence is part of more extended text, or if it belongs to a button, if its container has character constraints, etc.
This is a very complex point and I personally think that there is no easy solution to this, at least as far as content is exported from one environment (CMS) and imported into another one (XML > CAT Tools). If we had to find a solution to this, we could definitely think of plugins or other options that would allow the CAT tool to read the information contained into the XML (that must be customised to make sure it adds this information in it) and that would point directly to a possible staging environment in which the translator could see his/her translation in context.
This could be achieved by inserting a URL that would point to the page where to content is exported from and include it in the XML. The CAT tool should allow the translator to ‘preview’ the translation. By clicking on an option of this type, the tool would automatically upload the translated content to the CMS and open the page containing the translation into the browser. In this way the translator could make sure to understand if his/her translation is correct for that context and possibly correct it.
Such an option would solve many issues, especially linguistic and cosmetic ones. But there will be, however, issues that would not be possible to solve on the LSP side. These issues are generally depending on the client side and would be due to an incorrect internationalisation. Other difficulties in implementing such a solution would involve security and access matters, as to let a CAT tool automatically access a CMS, upload and manipulate data in it is not as simple as we can imagine.

Figure 7 – Example of internationalization issue (EU-OSHA website)
The above image is an example of incorrect internationalisation: the content containers do not expand according to the length of their content. A ‘workaround’ solution, for the first box (top left side), would be to insert a </br> tag in the text in the CAT tool editor in order to have the text in two lines, or by rephrasing it to make it shorter. Regarding the button ‘Informazioni partiche’ (bottom right side) the translator could try to rephrase it, like for instance ‘Info pratiche’, but style guides or content in Translation Memories could oblige the use of that form for coherence purposes, for instance. These kinds of workarounds can be put in place only if the translator can see the text in its context: when working with a CAT tool, the translator does not see if the text has to fit a given content container. That is the reason why we talk about ‘challenges’ and about Localisation, as there are a series of factors that are typical of the Localisation work and not of the traditional translation work.
Quality assurance: testing or quality control?
Another important aspect that would definitely show the difference between a traditional translation request and website localisation request (of this type or requests), is the need of a testing phase. It is actually a compulsory step in which translators or localisation engineers must make sure that the translated webpage is working from a cosmetic, linguistic and functional point of view.
This is done usually when the translation process is over and, in theory, should be done by translators which are able to solve any cosmetic and functional issues, in addition to linguistic ones. The reality is that not all translators are able to solve cosmetic or functional issues, as very technical skills might be required: be familiar with a CMS, knowing XML and HTML, etc.
Therefore, this task can be shared between translators and localization engineers: translators for linguistic issues, localisation engineers for cosmetic and functional issues – a close collaboration between the two profiles is required.
But if we consider the fact that these requests must undergo through several processes before being translated and that tasks must be shared between several profiles, and, finally, they have delivered to the client (and tested) through the CMS in less than 24 hours, we understand the a proper localisation testing is not possible. Therefore the type of testing carried out, by both translators and localisation engineers, would be a light testing or simply a quality control.
Delivery
Strictly linked to the previous paragraph, the delivery represents the final stage of this kind of localisation process. As it was mentioned above, translated content could be processed and uploaded to the client’s CMS automatically (maybe through the plugins in the CAT tool). There, it is checked to see if everything is fine, and finally the request is marked as completed in the CMS.
The delivery phase is therefore quite simple. At this stage the client would receive a notification by its own CMS telling that a task has been completed in the staging environment and that this task needs attention: the content must go live.
Final considerations and implications
In this paper I raised one question: is it possible to talk about Localisation when we look at European Union agencies websites? A brief analysis showed that we can talk about Localisation because of a series of technical factors that show that, although the cultural customisation experience in EU agencies website is low or absent in many cases, we are still in the position to talk about Localisation.
This analysis, might constitute just the starting point of a further detailed analysis on the topic of ‘Localisation or Standardisation inside EU Agencies Websites’, and extend towards a wider job. By highlighting the many challenges and issues still in place in various activities of the localisation job, it was possible to see that it is not that obvious to understand if there is a clear globalisation strategy behind.
Finally, I hope that this paper might still be useful to understand some of the real challenges of the Localisation job in the context of websites. I personally find that dealing with this kind of job is very fascinating and encouraging. Things change and develop constantly and it is always good to discover new features, processes and approaches as it pushes to keep curiosity alive and to always consider that there might be other solutions available around.
References:
[1] European Union Website: https://europa.eu/european-union/about-eu/eu-in-brief_en
[2] European Union Fundamental Rights Charter “The Union shall respect cultural, religious and linguistic diversity”: http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:12010P&from=EN#page=8
[3] Translation of the Italian title: Ottimizzazione della gestione di progetti di localizzazione di contenuto di pagine web create e gestite attraverso un sistema di gestione di contenuti. Il caso dell’Agenzia europea per la sicurezza e la salute sul lavoro e del Centro di traduzione degli organismi dell’Unione europea. Thesis presented in October 2015, at the International University of Menéndez Pelayo, Seville, Spain – Master in New technologies and translation: localization of software, videogames and multimedia products.
[4] Smartling, Be Everywhere (2014), What localisation for business really means [online], available: https://www.smartling.com/blog/localization-what-it-really-means-for-your-business/ [consulted: Dec 2016]
[5] Bert Esselink in A practical guide to Localization defines it in the following way: Localisation involves taking a product and making it linguistically and culturally appropriate to the target locale (country/region and language) where it will be used and sold’.
[6] Intersolinc, Website localisation [online], available: http://intersolinc.com/website_localization.html
[7] This is an example of XML file exported from the Client’s CMS and which is sent for translation to the LSP: some details have been hidden for confidentiality reasons.
Bibliography:
Antoni O., J.M. (2008). Traducción y Tecnologías. Barcelona: Editorial UOC.
Ehrensberger-Dow, M. (2014), “Challenges of translation Process Research at the Workplace”. MonTI Special Issue – Minding Translation (355-383).
European Commission, Directorate-General for Translation (2009), “Web translation as a genre”. Brussels.
Jiménez-Crespo, M. A. (2013). “Translation and Web. Localisation”. NY, London: Routledge.
M&C, What are the different types of websites? [online], available: https://www.methodandclass.com/article/what-are-the-different-types-of-website [consulted: Dec 2016]
Mayur Kadam (2014), Types of Websites [online], available: http://www.slideshare.net/NeilLohana/different-types-of-websites-31906656 [consulted: Dec 2016]
Medina, M y Morón, M. (2016) “La competencia del traductor que no “traduce”: el traductor en ámbitos de internacionalización empresarial”. MonTI: Monografías de traducción e interpretación. Nº. 8 (225-256).
Nitish Singh (2012), Localization Strategies for Global e-Business. Cambridge University Press, UK.
Sin-Wei, Chan (2015), Routledge Encyclopedia of Translation Technology. London: Routlegde.
Smartling, Be Everywhere (2014), What localisation for business really means [online], available: https://www.smartling.com/blog/localization-what-it-really-means-for-your-business/ [consulted: Dec 2016]
Young, Hoon Kwak (2003), “Brief History of Project Management”. The Story of Managing Projects by Carayannis, Kwak, and Anbari, Quorum Books, 2003.
Author Bio:
 Giuseppe Forte works as a Translation Technologist and Quality Coordinator at the Translation Centre for the Bodies of the European Union. He is responsible for CAT tools-related incidents, queries and training on the use of language technologies, maintenance and creation of translation resources, definition of translation and other services processes, testing and analysis, and website localisation quality checks.
Giuseppe Forte works as a Translation Technologist and Quality Coordinator at the Translation Centre for the Bodies of the European Union. He is responsible for CAT tools-related incidents, queries and training on the use of language technologies, maintenance and creation of translation resources, definition of translation and other services processes, testing and analysis, and website localisation quality checks.
With a Master’s degree in New Technologies for Translation: Localization of Software, Videogames and Multimedia Products, a Bachelor’s degree in Languages in the Information Society and as a Certified Terminology Manger, Giuseppe has several years of work experience in international organisations such the Food and Agriculture Organisation of the United Nations and the International Fund for the Agricultural Development of the United Nations as CAT Tools, Terminology, Reference and Translation Workflow Specialist.
His passion for Language Technology and multicultural environments led him to further investigate in the field of Global Digital Marketing and Localisation to ensure high quality translation products and localisation best practices.
please click here. The program offers dual credentials, with a Certificate from the University of North Carolina Wilmington and a Certification from The Localization Institute.




